Model as methodologist: an agent that runs the method, not a chatbot
The usual way to add AI to an app is to bolt on a chatbot. The stronger pattern inverts it: the model runs the method, the app is just its hands.
The default way to put AI into a domain app is to bolt a chatbot onto an existing product. Generate an exercise on demand, answer a question, summarize a document. The app stays in charge; the model is a feature inside it.
There’s a stronger pattern, and it inverts the relationship: the model runs the method, and the app is the set of hands it works through. The product becomes a system of record — a database with a strict set of operations — and the model makes the decisions that used to be compiled into code.
We’ll walk through it with a concrete example: a language tutor built for a single learner’s Swedish. There is no course in it. The model is the methodologist, the app is its hands.
The problem the method has to solve
Most language tools, and most exams, test recognition: fill the gap, pick the option, rewrite the sentence into the passive. You can score consistently high on a pattern you have never produced unprompted. Recognition climbs, production stalls, and the learner reaches for the same handful of safe constructions every time they actually write.
Closing that gap isn’t a content problem — there’s no shortage of exercises. It’s a decision problem. Something has to look at where recognition and production diverge for this specific learner this week, and decide what to work on next. That “something” is exactly the kind of judgment that’s expensive to hard-code and easy to get wrong, because it changes every session.
So instead of writing the decision logic, we hand it to the model.
How it works
The model runs a methodologist’s loop on every session: read the current state, decide what to teach, grade what the learner produced, write the results back. Four moves, each backed by the app.
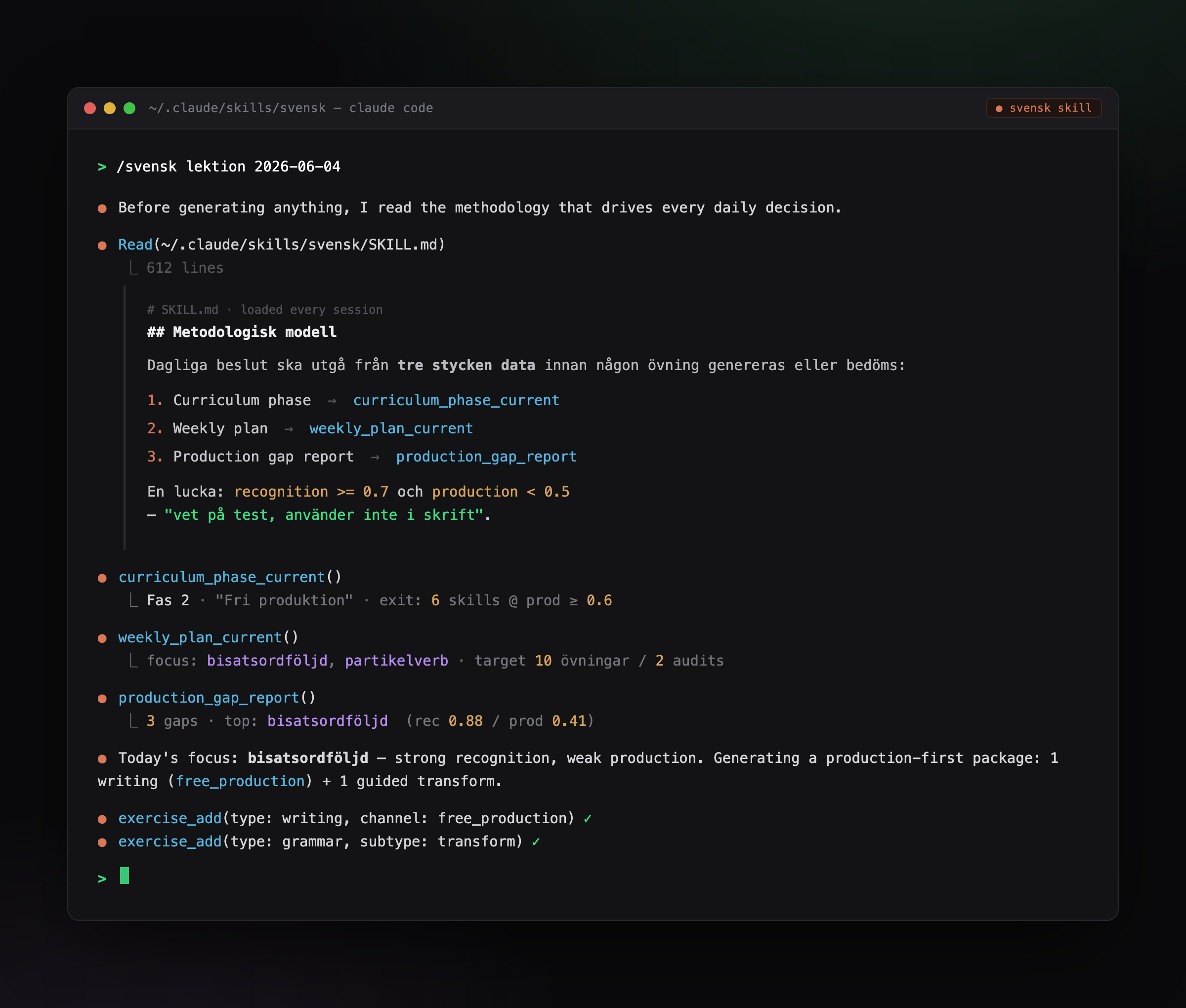
Read state. Before it does anything, the agent reads the learner model: which curriculum phase they’re in, the week’s plan, and a per-skill report of where they score high in drills but never produce the pattern in free writing. That report is the input to the teaching decision, not a chat history.
Decide. From that state the model picks what to focus on. The patterns the learner “knows” but never produces float to the top. This is a methodologist looking at a student and choosing the next move — not a chatbot answering a prompt.
Grade. The learner writes one short journal entry in Swedish. The model grades it, logs the errors, and records a per-skill audit of what was used correctly versus avoided. Each skill carries two scores, not one: recognition and production. The recognition signal is cross-checked against the learner’s Anki deck rather than guessed.
Write back. Advancing the curriculum phase, leaving structured notes in a tutor’s notebook, recomputing what to teach next — all of it is persisted. The learner never touches any of it.
The mechanism underneath is unglamorous. The Wails desktop app (Go backend, embedded webview, Lit frontend, local SQLite) exposes every data-mutating operation — about 45 of them — as a tool: read the error bank, write a grade, advance the phase, leave a note. The Claude Agent SDK runs as a persistent sidecar and calls those tools through MCP. It’s the same tool-use loop that’s behind Claude Code, pointed at the database of one learner.
The move that makes it worth doing
The teaching method isn’t in the code. It’s a plain-text file the model loads at the start of every session — editable, no redeploy. Change the pedagogy and the next session reflects it.
That’s the whole point of the inversion. The app is the part you want stable and auditable: a schema, a fixed set of operations, a permission boundary around writes. The method is the part you want to change often and reason about in plain language. Putting the method in code couples the two and makes every pedagogical tweak a deploy. Putting it in a file the model reads keeps the system of record stable and the judgment flexible.
What it costs to run
There’s no hosting bill — the app runs on the learner’s own machine, and SQLite means no database to operate. The only variable cost is the Claude API: roughly one agent session per study day, each a short read-decide-grade-write loop rather than an open-ended chat. The expensive engineering was up front — defining the ~45 operations and their permission tiers, and getting the learner-state report right so the model has something real to decide from.
When this pattern fits
This isn’t about language learning. It’s a pattern: the model runs the method, the app is a stateful system of record exposing a fixed set of tools. It fits when:
- The work is a recurring decision, not a one-off answer — what to do next depends on accumulated state, not just the latest message.
- That state changes over time and has to be written back (scores, phases, logs, notes), not just read.
- The judgment is worth changing often, so you want it in editable plain text rather than compiled into the app.
- You want a hard boundary around writes — a fixed set of operations the model can call, each with its own permission, instead of free-form access.
A compliance reviewer that reads a case file, decides what’s missing, and updates the case record. An onboarding coach that tracks where each new hire is stuck and sequences the next task. A training system that maintains a competency model per employee and recomputes what to assign. Same shape: a plain system of record, a fixed tool surface, and the method living in a file the model loads each run.